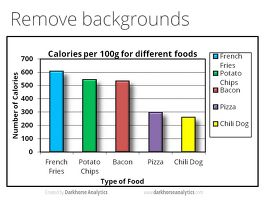
데이터 (7) 썸네일형 리스트형 빅데이터에 이어 생활데이터의 시대가 온다 빅데이터는 이제 우리 생활에서 떼려야 뗄 수 없는 것이 되어버렸습니다. 일상생활 속의 문제를 해결하거나 불편한 점을 개선해주는 역할을 하면서, 빅데이터는 점점 더 우리의 일상과 긴밀한 관계를 유지해 가고 있습니다. 하지만 빅데이터가 모든 문제를 해결해 줄 수는 없습니다. 우리의 생활에서 사소하게 일어나는 문제에 대해서는 특히 더 그렇습니다. 그래서 주변 생활 속에서 발생하고 쌓이는 데이터, 즉 ‘생활 데이터’가 필요하게 되는 것입니다. 생활 데이터는 데이터가 주는 본질적인 의미보다 기술과 장비에 치중하게 되는 요즘의 ‘빅데이터 세태’에 반하여 나온 개념입니다. 우리 주변에서 발견할 수 있는 아주 작은 데이터라도 그것을 활용하고 이해하는 과정이 중요하다는 것을 강조하는 것이지요. 관련 전문가가 아니더라도,.. 디자이너를 위한 엑셀 활용법 2 들어가며지난 글 “디자이너를 위한 엑셀 활용법”에 이어 엑셀을 실무에 사용할 수 있는 몇 가지 팁을 소개하고자 합니다. 지난 글과 함께 읽어도 좋지만 이어지는 내용은 아니니 편하게 읽어 주시기 바랍니다. 활용1. ‘0’으로 시작하는 텍스트 입력하기셀에 입력한 단어, 숫자의 맨 앞자리가 이유 없이 사라지는 경우가 있습니다. 대표적인 경우가 등호(=)와 0(숫자 ‘영’)을 입력하는 경우입니다. 등호(=)는 함수나 계산 식을 입력할 때 사용하므로 그 뒤에 어떤 단어를 붙이면 등호가 사라지거나 입력이 되지 않고 오류를 표시합니다. 또한, 0을 맨 앞자리에 입력할 때 엑셀은 맨 앞자리의 0을 무시하기 때문에 ‘010’으로 시작하는 휴대전화 번호를 입력해도 ‘10...’으로만 표시됩니다.이런 경우에는 셀의 맨 앞에.. 데이터를 잘 써먹을 수 있는 구체적인 방법 한동안 분야를 막론하고 '데이터' 혹은 '빅데이터'의 열풍이 몰아친 적이 있었습니다. 그 열기는 한 김 식었고 그 뒤에 감추어져 있던 거품이 모습을 드러내기도 하였지만, 데이터는 여전히 어떤 '가치'를 창출하는 데 있어 중요한 수단으로 여겨지고 있습니다. 치열한 경쟁 속에서 살아남기 위해서 데이터의 사용은 더욱 필요할 것이며, 기술의 발전은 그러한 적용을 수월하게 만들 것입니다. 과연 데이터 시대에서 우리는 가치 있는 데이터를 잘 사용하고 있을까요? 많은 데이터를 가지고 있는 것 또는 그러한 데이터를 사용하는 행위 자체에 어떤 의미를 부여하며, 데이터 사용의 본질을 잊고 있는 것은 아닐지 고민해 보아야 합니다. 효율적인 의사 결정을 지원하는 정보라는 관점에서 데이터를 잘 활용하기 위해서는 어떻게 해야 하.. ed:m, 당신의 이름을 함께 만들다 (2) 리브랜딩이란 단순히 로고를 예쁘고 새롭게 만드는 것에서 끝나는 것이 아닙니다. 브랜드의 새로운 비전과 철학에 맞지 않는 옷을 입은 로고는 오래 갈 수 없습니다. 새롭게 태어난 브랜드의 말과 행동부터 모든 걸 새롭게 재설계해야 지속할 수 있습니다. 브랜드의 맞춤옷을 위해 걸음걸이와 습관을 살펴본 것이 데이터 분석이었다면, 이제 본격적인 설계와 구현에 들어가는 과정입니다. > 먼저 읽기 : ed:m, 당신의 이름을 함께 만들다 (1) edm이 ed:m이 되다 – 유학은 ‘경험’이 핵심 키워드다 슬로워크: 기존 유학 시장을 분석해 보니 ‘상업적, 돈’과 같은 부정적 이미지가 있었어요. 유학의 동기가 ‘스펙’만이 아니라는 것도 확인했고요. 이제는 유학을 자신이 원하는 경험과 배움을 찾기 위해 가는 과정으로 봐야.. 두 소녀의 핸드드로잉 인포그래픽 'Dear Data' 디지털 기술의 발달로 편리한 정보 수집과 생산, 가공이 가능해졌습니다. 덕분에 우리의 삶은 편리해졌지만, 넘쳐나는 정보에 허우적 거리다 보면 소소한 일상에 대한 관심은 줄어갑니다. 오늘은 조금 다른 방식의 인포그래픽을 선보이고 있는 두 디자이너를 소개 합니다. 소소한 일상 속에서 의미를 찾아 아날로그하게 표현하는 조지아와 스테파니의 ‘Dear Data’ 입니다. 조지아 Giorgia Lupi (왼쪽)조지아는 이탈리아인이고, 현재 뉴욕 데이터 전문 회사에서 인포그래픽 디자이너로 일하고 있습니다. 그녀는 무질서한 것들을 모아 질서를 만들고, 아날로그 방식으로 표현하는것을 좋아합니다. 스테파니 Stefanie Posavec (오른쪽)스테파니는 미국인이고, 런던에서 살고 있습니다. 프리랜서 인포그래픽 디자이너로.. 디자이너 부럽지 않은 인포그래픽 만들기 많은 정보를 한눈에 보기 쉽게 만들기 위해 표나 그래프를 만들 때 어떤 툴을 사용하시나요? 슬로워크에서는 다양한 정보를 시각화하기 위해 adobe사의 일러스트레이터를 가장 많이 사용하는데요. 워드나 한글, 파워포인트에서도 표나 그래프를 쉽게 만들 수 있지만, 글과 그래프의 연결 혹은 전체 내용을 어우르는 인포그래픽을 만들기 위해서 문서도구보다는 그래픽 툴인 adobe의 일러스트레이터로 훨씬 쉽게 인포그래픽을 만들 수 있기 때문이지요. 하지만 일반들이 멋진 그래프를 만들기 위해 디자인 툴을 다루기엔 그 진입장벽이 엄청 높습니다. 그렇다고 일일이 디자인회사에 맡기기엔 그 비용이 어마어마한데요. 문서도구로는 많은 시간과 노력이 필요한 인포그래픽 작업을 일반인도 쉽고 간단하게 만들 수 있는 웹사이트를 소개하려합.. 깔끔한 그래프를 만드는 방법, “지우기” 얼마전 인터넷에 “그래프를 더 멋지게 만들기”라는 제목으로 떠돌던 움직이는 그림(gif)이 있었습니다. 아래 그림을 보시면 우리가 흔히 볼 수 있는 그래프를 어떻게 더 간결하게 바꿀 수 있는 방법을 단계별로 보여주고 있습니다. The Dark Horse Analytics라는 데이터 시각화 전문회사가 만든 슬라이드인데요. 원문 Data looks better naked를 보시면 더욱 자세한 설명을 보실 수 있습니다. 그럼 간결한 그래프를 위한 방법을 단계별로 살펴 보겠습니다. 1. 배경을 지워라.그래프 아래 깔려 있는 나무 질감과 회색 배경이 사라졌습니다. 특히 나무 질감의 배경은 데이터와 큰 상관이 없는 것 같네요. 2. 라벨(범례)를 지워라. 그래프 우측의 범례와 축의 제목을 지우라고 합니다. 상단의 .. 이전 1 다음